Intranet - VIDIAS.
Arbeitsablaufsdefinitionen mit dynamischen Anteilen.
Die Daten des Gesamtverzeichnisses werden verwendet, um entsprechende Arbeitsablaufsdefinitionen für die verschiedenen Inhaltstypen der im Intranet abzubildenden Prozeßabläufe zu generieren und somit für eine Verwendung in der Ploneinstanz des Intranets zur Verfügung zu stellen.
Um die Plone Arbeitsabläufe für einen Einsatz im Intranet generieren zu können, stellt die Anwendung Gesamtverzeichnis einen eigenen Satz an Definitionen für Arbeitsabläufe, Zustände, Zustandsübergänge, Berechtigungen und Berechtigungsrollenzuweisungen zur Verfügung, welche als Grundlage für eine Generierung dienen. Diese zusätzlichen Definitionen mögen redundant erscheinen, jedoch bietet Plone keine Möglichkeit, Zustände und Zustandsübergänge von Arbeitsabläufen automatisch zu generieren. Eine automatische Generierung ist jedoch notwendig, da die Anzahl der benötigten Zustands- und Zustandsübergangsdefinitionen im drei bis vierstelligen Bereich liegt. Daher wurde der Ansatz gewählt, Arbeitsablaufsdefinitionen außerhalb von Plone definieren zu können, und aus diesen Definitionen dann mittels Python-Django die erforderlichen umfangreichen Arbeitsablaufsdefinitionen generieren zu können. Hierbei kommen entsprechende Platzhalter in den Zustands- und Übergangsdefinitionen zum Einsatz, welche die automatische und zum Teil mehrfach rekursiven Generierungsprogrammroutinen steuern.
Auch können einmal definierte Zustände und Übergänge in verschiedenen Arbeitsabläufen wiederverwendet werden.
Pro Arbeitsablauf gibt es eine Generierungsroutine als Python-Django runscript Implementierung im Verzeichnis plone/scripts. Wiederverwendbare Quelltextanteile zur Generieurng von Arbeitsabläufen befinden sich in der Basisklasse arbeitsablauf_basis.py. Für jeden Arbeitsablauf gibt es eine von dieser Basisklasse abgeleitete Klasse in einer eigenen Datei, welche nach einem einheitlichen Namenschema benannt wird: arbeitsablauf_<arbeitsablaufsname>.py.
Zusätzlich gibt es für jeden Arbeitsablauf ein eigenes Ausführungsskript, welches nach dem Bezeichner des Arbeitsablaufes selber benannt ist. Beispiel: admin.py für die Generierung des Adminarbeitsablaufes. Diese Skripte sind generisch und rufen die Generierungsroutine der entsprechenden anbgeleiteten Klassen mit entsprechenden Parametern auf.
Generierung von Arbeitsabläufen.
Um die Generierung von Sätzen von Arbeitsabläufen für bestimmte Datenbestände zu vereinfachen, steht ein entsprechendes Verwaltungskommando mit dem Namen arbeitsablaeufe zur Verfügung. Dieses wird mittels
(.venv) $ python {manage.py|managetestdaten.py|managetestdatenarbeitsablauf.py} arbeitsablaeufe
aufgerufen und listet standardmäßig alle verfügbaren Arbeitsabläufe auf. Mit dem zusätzlichen Parameter alle wird eine Generierung für alle Arbeitsabläufe angestoßen. Es können auch einzelne Arbeitsabläufe ausgewählt werden, in dem die Namen entsprechend durch Leerzeichen getrennt als Parameter mit angegeben werden. Also
(.venv) $ python {manage.py|managetestdaten.py|managetestdatenarbeitsablauf.py} arbeitsablaeufe standard admin
um die beiden Arbeitsabläufe admin und standard zu generieren.
Nach einem erfolgreichen Generierungslauf stehen die erzeugten einsatzbereiten Arbeitsablaufsdefinitionen für die jeweilige Plone-Instanz in einer eingepackten *.tgz-Datei zu Verfügung (Ort der *.tgz-Datei wird angezeigt).
Datenbestände.
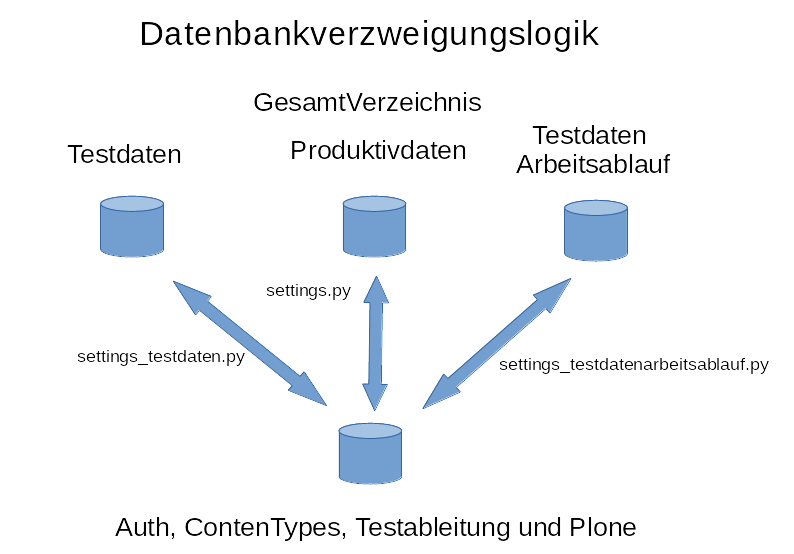
Es besteht die Möglichkeit, mehrere Datenbestände an Verzeichnisdaten parallel zu fahren. Um Redundanz bei den Daten der anderen
python-django Module zu vermeiden, kommt eine Datenbankverzweigungslogik zur Anwendung, welche sich in einer entsprechenden routers.py Datei im Ordner
anwendung_gesamtverzeichnis/anwendung_gesamtverzeichnis befindet.
Beim Aufruf von Python-Django Verwaltungskommandos kann durch Auswahl der entsprechenden manage.py-Datei der entsprechende Datenbestand ausgewählt werden. Zur Zeit stehen drei Datenbstände zur Verfügung:
produktiv - Datenbestand für die Produktivumgebungen.
testdaten - Datenbestand mit einem oder zwei Direktorien zu manuellen Testzwecken und zur Einführung des VIDIAS-Systemes.
testdatenarbeitsablauf - Vereinfachter Datenbestand, welcher sämtliche möglichen Aufgabenstellungen in einfachster Weise abbildet.
Dieser Datenbestand wird in der automatischen Testabdeckung verwendet.
Integrationstests auf Ebene von Python-Django.
Die Integrationstests für die generierten Arbeitsabläufe (XML-Dateien) auf python-django Ebene befinden sich im Plone-Modul der Anwendung Gesamtverzeichnis im Ordner tests.
Ein Integrationstest deckt folgende Elemente einer generierten Arbeitsablaufdefinition ab:
Verwendete Gruppen
Verwendete Berechtigungen
Verwendete Zustände
Verwendete Zustandsübergänge
Es wird auf dieser Ebene der Tests (Ebene der python-django Anwendung Gesamtverzeichnis) lediglich auf das Vorhandensein der erforderlichen Elemente geprüft. Die eigentliche Funktionalität eines Arbeitsablaufes wird auf Ebene der Anwendung Plone mit zusätzlichen Tests laut Testdrehbuch abgdeckt.
Bemerkung
Ein Integrationtest für einen neuen Arbeitsablauf auf python-django- sowie auf Plone-Ebene ist eine Grundvorraussetzung für einen Einsatz in der Produktivumgebung des VIDIAS-Systemes.
Aufruf der Tests.
Die Tests werden durch den Aufruf des mitgelieferten Python-Django-Verwaltungskommandos test aufgerufen. Die Auswahl einzelner Tests ist durch Angabe des Pfades zur Testklasse mittels der python-üblichen Punktnotation möglich.
Beispiel: python manage.py test ruft sämtliche Tests auf oder python manage.py plone.tests.test_generiere_arbeitsablauf_admin um nur die Tests dieser einen Klasse aufzurufen.
Verwendeter Datenbestand der Testabdeckung.
Die Datenbestände für Tests sind fest in json-Dateien gespeichert und werden automatisch bei jedem Aufruf eines Tests in eine leere Testdatenbank hineingeladen.
Die Erzeugung von Testdatenbeständen geschieht mittels entsprechendem Verwaltungskommando im Plone-Modul.
(.venv) $ python managetestdatenarbeitsablauf.py erzeugeplonetestfixtures
erzeugt feste Datenbestände zur Durchführung der Tests auf Grundlage der gespeicherten Daten im Datenbstand testdatenarbeitsablauf.
Die Tests sind in der Regel an den Datenbestand testdatenarbeitsablauf angepaßt. Zukünftige Tests sollten diesen auch verwenden und bei Bedarf entsprechend anpassen/erweitern. Hierbei ist es wichtig, daß alle vorhandenen Tests weiter sauber durchlaufen. Nur so ist eine abgesicherte weitere Entwicklung der Anwendung möglich.